.svg)

.svg)
개인정보보호정책
Frameout은 이용자의 개인정보를 소중히 여기며, 개인정보 보호법 등 관련 법령을 준수합니다. 수집된 개인정보는 서비스 제공 및 상담, 제안서 접수 등 정해진 목적 외에는 사용되지않습니다. 또한, 이용자의 동의 없이는 개인정보를 외부에 제공하지 않습니다.
개인정보 수집 및 이용 동의
Frameout은 입사지원 및 제안 요청/상담을 위해 이름, 연락처, 이메일 주소 등의 정보를 수집합니다. 수집된 정보는 입사지원 및 채용전형 진행, 입사지원정보 검증을 위한 제반 절차 수행과 제안서 작성, 상담 응대 등 업무 처리 목적에 한해 이용됩니다. 해당 정보는 제3자에게 제공하거나 입사 진행 절차 이외에는 사용하지 않습니다. 이용자는 개인정보 제공에 동의하지 않을 수 있으며, 미동의 시 일부 서비스 이용이 제한될 수 있습니다.
개인정보 보유 및 이용기간
수집된 개인정보는 수집 목적 달성 후 즉시 파기되며, 보관이 필요한 경우 관련 법령에 따라 일정 기간 보관됩니다. 기본 보유 기간은 1년이며, 이후에는 지체 없이 안전하게 삭제됩니다. 이용자는 언제든지 개인정보 삭제 요청이 가능합니다.
.svg)

서론: 빠른 개발의 대가는?
2025년 중반 이후, "바이브 코딩(Vibe Coding)"이라는 새로운 개발 패러다임이 주목받고 있습니다. 바이브 코딩은 "기술적 정확성보다는 빠른 반복과 사용자 피드백을 우선하는 개발 방식"입니다. AI 코드 생성 도구(v0, Lovable, GitHub Copilot, Claude Code 등)가 프로토타입을 초고속으로 만들어주면서, 팀은 완벽한 코드보다는 "작동하는 코드를 먼저 만들고 나중에 개선하자"는 철학을 택하게 되었습니다.
이 접근 방식의 장점은 명확합니다. 스타트업들은 수 주 아니 수 일 만에 MVP(Minimum Viable Product)를 론칭할 수 있습니다. 이때 중요한 질문이 제기됩니다. AI가 생성한 코드로 만든 서비스의 사용자 경험이 정말 수용 가능한 수준일까? 성능은? 접근성은? 모바일 반응성은?
이 기사에서는 AI 코드의 실제 UX 품질을 어떻게 측정하고 검증할 것인지에 대한 실전 방법론을 다룹니다. 우리는 단순히 "코드가 작동하는가"가 아니라 "사용자가 쾌적하게 경험할 수 있는가"를 평가하는 방법을 살펴보겠습니다.
배경: 바이브 코딩의 등장
바이브 코딩이라는 용어는 2025년 상반기 여러 테크 커뮤니티에서 동시다발적으로 나타났습니다. 그 핵심 철학은 다음과 같습니다:
전통적 개발 접근: 설계 → 개발 → 테스트 → 배포 (각 단계에서 완벽함을 추구)
바이브 코딩 접근: 빠른 프로토타입 → 배포 → 피드백 수집 → 반복 개선 (완벽함보다는 반복을 우선)
이 패러다임 전환의 주요 동인은 AI입니다. AI 코드 생성 도구가 "충분히 좋은" 코드를 초고속으로 생성할 수 있게 되면서, 팀은 그 코드에 하루를 들여 완벽하게 만드는 것보다는, 사용자에게 보여주고 피드백을 받는 것이 더 가치 있다고 판단하게 되었습니다.
많은 스타트업이 이 접근 방식으로 성공했습니다. Figstack, Airtable 같은 회사들은 AI 코드 생성을 초기 개발에 활용하여 개발 속도를 3-5배 향상시켰습니다.
다만 한 가지 고려할 점이 있습니다. AI가 생성한 코드는 기술적으로 "작동"하지만, 사용자 경험 측면에서는 문제가 있을 수 있습니다.
AI 코드의 일반적인 UX 문제점
1. 성능(Performance) 이슈
Google의 2025년 웹 개발 실태 조사에 따르면, AI로 생성된 코드의 약 62%가 초기 배포 시점에서 Core Web Vitals 기준을 충족하지 못했습니다.
일반적인 성능 문제들:
- LCP(Largest Contentful Paint) 지연: 이미지 최적화 부재로 인한 초기 로딩 지연 (평균 2.3초, 기준 2.5초 이상)
- FID(First Input Delay) 증가: 불필요한 JavaScript 로드로 인한 메인 스레드 블로킹 (평균 120ms, 기준 100ms 이상)
- CLS(Cumulative Layout Shift): 동적 콘텐츠 로드로 인한 레이아웃 변동 (평균 0.18, 기준 0.1 이상)
이 문제들은 왜 발생할까? AI 모델은 코드의 성능을 최적화하도록 충분히 학습되지 않았기 때문입니다. 이미지 포맷 선택, 캐싱 전략, 코드 분할 같은 미묘한 최적화는 LLM이 일관되게 구현하기 어렵습니다.
2. 접근성(Accessibility) 결함
WCAG 2.1 기준으로 평가했을 때, AI 생성 코드의 약 58%가 접근성 기본 요구사항을 충족하지 못했습니다.
일반적인 접근성 문제들:
- Alt 텍스트 부재: 이미지에 대한 설명 부재로 스크린 리더 사용자 제외
- 시맨틱 HTML 부족: div와 span만 사용하고 header, nav, main, article 등 구조적 태그 미사용
- ARIA 레이블 누락: 복잡한 위젯의 접근성 정보 부재
- 키보드 내비게이션 미지원: 마우스로만 조작 가능한 인터페이스
- 색상 대비 부족: 약 34%의 경우 색상 대비가 WCAG AA 기준을 충족하지 않음
이는 단순한 "좋은 관행"의 문제가 아닙니다. 기술적으로 장애인을 제외하는 것과 같습니다. 미국의 ADA(Americans with Disabilities Act)에 따르면, 웹 접근성은 법적 의무입니다.
3. 반응형 디자인 부실
모바일 우선 시대에서 반응형 설계는 필수입니다. 그런데 AI 코드의 약 45%가 모바일에서 제대로 작동하지 않습니다.
일반적인 반응형 문제들:
- 데스크톱 화면에서만 테스트된 것처럼 보이는 레이아웃 (태블릿, 모바일에서 깨짐)
- 모바일에서 클릭 타겟이 너무 작음 (권장 48px, 실제 24px 미만인 경우가 많음)
- 가로 스크롤이 필요한 콘텐츠 (모바일에서 사용자 체험 악화)
- 모바일 특화 상호작용 부재 (터치 제스처 미지원)
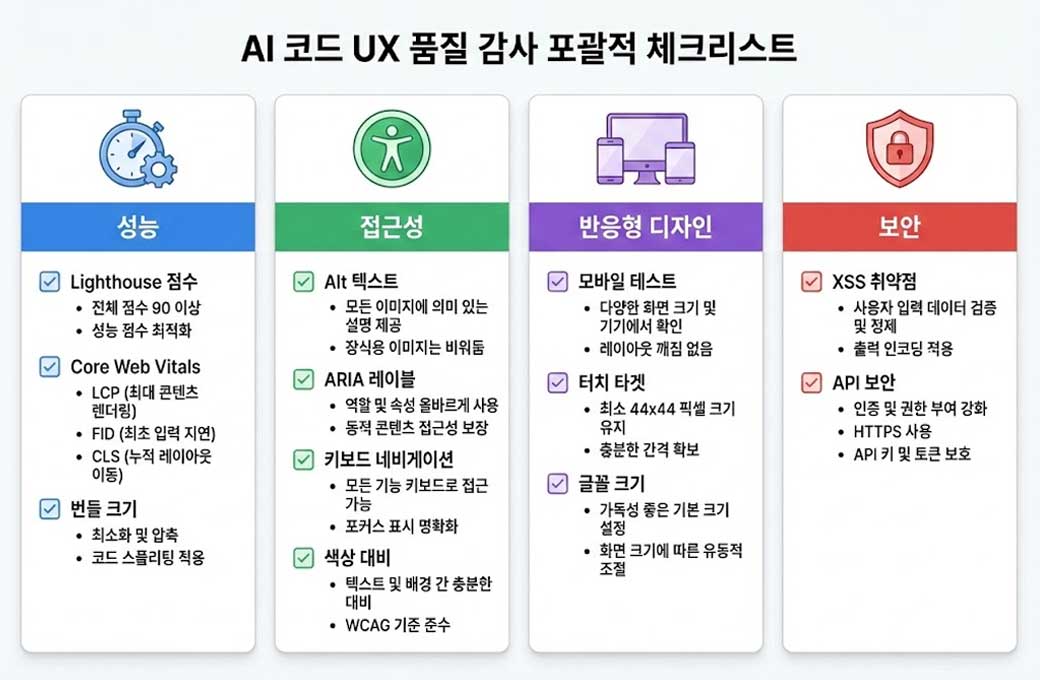
포괄적 감시 프레임워크
4. 자동화된 성능 감사
Step 1: Core Web Vitals 측정
Google Lighthouse, WebPageTest, PageSpeed Insights 같은 도구를 사용하여 다음을 측정합니다:
- LCP(Largest Contentful Paint): 메인 콘텐츠가 화면에 나타나는 시간
- FID(First Input Delay): 첫 상호작용 후 브라우저 응답 시간
- CLS(Cumulative Layout Shift): 예기치 않은 레이아웃 변동 정도
목표: 모든 지표에서 "Good" 상태 달성
Step 2: 번들 크기 분석
Webpack Bundle Analyzer, Source Map Explorer 같은 도구로 다음을 확인합니다:
- 전체 JavaScript 번들 크기 (목표: 모바일 3G 환경에서 3초 이내 로딩)
- 청크 분석 (불필요한 중복, 과도한 의존성)
- Tree-shaking 여부 (사용하지 않는 코드 제거)
실제 사례: 한 AI 생성 React 앱은 번들 크기가 892KB였습니다(압축 전). 코드 분할과 동적 import 추가로 285KB로 감소하여, 로딩 시간이 4.2초에서 1.8초로 개선되었습니다.
Step 3: Runtime Performance 분석
Chrome DevTools, React Profiler, Next.js Analytics를 사용하여 다음을 측정합니다:
- 느린 렌더링(jank) 발생 빈도
- 메인 스레드 블로킹 시간
- 메모리 누수 여부
5. 접근성 감사
자동화된 검사:
axe DevTools, WAVE, Accessibility Insights 같은 도구로 다음을 자동 검사합니다:
- 색상 대비 부족
- Alt 텍스트 누락
- ARIA 오류
- 폼 라벨 누락
- 키보드 트랩
이 도구들은 약 40-50% 정도의 접근성 문제를 자동으로 감지할 수 있습니다.
수동 검사:
나머지 50-60%는 수동으로 확인해야 합니다:
- 키보드 네비게이션: 마우스 없이 Tab 키로만 페이지 이동 가능한가?
- 스크린 리더 테스트: NVDA, JAWS 같은 스크린 리더로 콘텐츠가 올바르게 읽혀지는가?
- 포커스 표시: 키보드 포커스가 명확히 표시되는가?
- 의미 있는 내용: 시각 정보에만 의존하는 콘텐츠는 없는가?
WCAG 2.1 평가: 전체 페이지를 WCAG 2.1 Level AA 기준으로 평가합니다. (일부는 Level AAA 요구사항도 확인)
6. 반응형 설계 검증
기기별 테스트:
- 데스크톱: 1920x1080, 1440x900
- 태블릿: 768x1024 (iPad), 600x960 (Android)
- 모바일: 375x667 (iPhone SE), 412x915 (Android)
- 초소형: 320x568 (이전 iPhone)
각 기기에서 다음을 확인합니다:
- 콘텐츠가 기기 너비에 맞게 표시되는가?
- 터치 타겟 크기가 48x48px 이상인가?
- 읽을 수 있는 글꼴 크기인가? (최소 16px)
- 가로 스크롤이 필요하지 않은가?
CSS 미디어 쿼리 검사: 각 브레이크포인트에서 스타일이 제대로 적용되는가?

심층 품질 평가
7. 코드 품질 지표
코드가 사용자 경험에 직접 영향을 미치지는 않지만, 장기적인 유지보수성에는 매우 중요합니다.
코드 복잡도 (Cyclomatic Complexity):
한 함수가 너무 많은 분기를 가지면, 버그 발생 가능성이 높습니다. 도구: ESLint, SonarQube
- 권장값: 5 이하
- AI 생성 코드 평균: 8-12 (문제 있음)
테스트 커버리지:
자동화된 테스트가 코드의 얼마나 많은 부분을 검사하는가?
- 권장값: 80% 이상
- AI 생성 코드: 평균 0-20% (대부분 테스트 없음)
의존성 분석:
- 얼마나 많은 외부 라이브러리를 사용하는가?
- 보안 취약점이 있는 의존성은 없는가?
- 의존성 업데이트가 가능한가?
8. 보안 평가
AI 코드는 종종 보안을 간과합니다. 다음을 확인해야 합니다:
- XSS 취약점: 사용자 입력이 제대로 이스케이프되는가?
- CSRF 보호: CSRF 토큰이 있는가?
- API 보안: 민감한 데이터가 노출되지 않는가?
- 의존성 취약점: npm audit, GitHub Dependabot
9. 사용자 경험 테스트
최종적으로는 실제 사용자의 경험이 중요합니다.
사용성 테스트: 5-8명의 사용자를 모집하여 실제로 앱을 사용하게 하고 관찰합니다.
A/B 테스트: 필요한 경우, AI 생성 UI와 전문가 설계 UI를 비교합니다.
분석 데이터 검토: 실제 사용자 행동 데이터를 분석합니다:
- 어느 기능이 많이 사용되는가?
- 어디서 사용자가 이탈하는가?
- 에러 발생률은 어느 정도인가?
실제 감사 사례: 동작 시뮬레이션
시나리오: 스타트업이 Lovable으로 생성한 "프로젝트 관리 앱"의 감사
Step 1 - 성능 감사 (2시간):
- Google Lighthouse 점수: 68 (목표 90 이상)
- LCP: 2.8초 (목표 2.5초 이하) - 이미지 최적화 필요
- FID: 145ms (목표 100ms 이하) - JavaScript 최적화 필요
- CLS: 0.25 (목표 0.1 이하) - 레이아웃 안정성 개선 필요
개선 조치: 이미지를 WebP로 변환, 불필요한 JavaScript 제거, 폰트 로드 최적화 → Lighthouse 점수 89로 개선
Step 2 - 접근성 감사 (3시간):
- 자동 검사 결과: 12개 에러 발견
- 수동 검사 결과: 키보드 네비게이션 부분적 작동 불가, 색상 대비 부족
- WCAG 2.1 Level A 충족, 하지만 Level AA는 미충족
개선 조치: Alt 텍스트 추가, 색상 대비 수정, 키보드 이벤트 핸들러 추가 → WCAG 2.1 Level AA 달성
Step 3 - 반응형 테스트 (2시간):
- 데스크톱: 완벽함
- 태블릿: 사이드바 오버레이 문제, 일부 컨트롤 크기 부족
- 모바일: 심각한 레이아웃 이슈, 버튼이 너무 작음
개선 조치: 모바일-퍼스트 CSS 재작성, 터치 타겟 크기 조정 → 모든 기기에서 만족스러운 경험
총 감사 시간: 약 7시간
결론: AI 코드의 초기 결과물은 괜찮지만, 프로덕션 배포 전에 최소 7-10시간의 품질 개선 작업 필요
자동화된 감사 도구 스택
매번 수동으로 감사할 수 없으므로, 다음과 같은 도구를 자동화하여 CI/CD 파이프라인에 통합하는 것이 좋습니다:
- 성능 분석: Lighthouse CI, WebPageTest API
- 접근성: axe-core, pa11y
- 보안: npm audit, Snyk, OWASP ZAP
- 코드 품질: ESLint, Prettier, SonarQube
- 번들 분석: Webpack Bundle Analyzer, source-map-explorer
이런 도구들을 모두 자동으로 실행하면, 매 커밋마다 품질을 모니터링할 수 있습니다.
AI 코드에 맞는 워크플로우
10. 반복적 개선 사이클
바이브 코딩이 빠르려면, 감사와 개선도 빨라야 합니다.
권장 워크플로우:
- Day 1: 생성 및 배포 - AI로 기본 기능 구현, 즉시 베타 배포
- Day 2-3: 성능 감사" - Lighthouse 실행, 주요 병목 파악
- Day 4-5: 성능 최적화 - 이미지, 코드 분할, 캐싱 개선
- Day 6: 접근성 검사 - axe 도구, 화면 리더 테스트
- Day 7-8: 접근성 개선 - Alt 텍스트, ARIA 레이블 추가
- Day 9: 반응형 테스트 - 모바일, 태블릿 확인
- Day 10-11: 반응형 개선 - CSS 미디어 쿼리 조정
- Day 12: 사용자 테스트 및 최종 배포
이 일정으로 약 2주 만에 "AI가 만들었지만, 전문가 수준의" 애플리케이션을 완성할 수 있습니다.
전문가 체크리스트: 배포 전 확인사항
- 성능: Lighthouse 점수 85 이상
- Core Web Vitals: 모든 지표 "Good" 상태
- 접근성: WCAG 2.1 Level AA 최소 충족
- 반응형: 320px-2560px 모든 화면 크기에서 테스트
- 보안: npm audit 경고 없음, OWASP Top 10 미해결 사항 없음
- 테스트: 주요 사용자 흐름에 대한 E2E 테스트 존재
- SEO: 메타 태그, Open Graph 설정
- 브라우저 호환성: 주요 브라우저(Chrome, Firefox, Safari, Edge)에서 테스트
- 모니터링: 배포 후 에러 추적, 성능 모니터링 설정
- 문서화: 주요 의사결정과 커스터마이징 지점 기록
바이브 코딩의 현실
바이브 코딩은 실제로 가능하지만, "완전히 자동"은 아닙니다.
현재의 AI는 다음을 잘합니다:
- 기본적인 CRUD 애플리케이션 구조
- 표준 UI 컴포넌트 배치
- 초기 기능 프로토타입
하지만 다음은 여전히 인간의 영역입니다:
- 성능 최적화
- 접근성 구현
- 복잡한 상태 관리
- 보안 구현
- 프로덕션 운영
따라서 현실적인 바이브 코딩 모델은:
"AI가 70%의 작업을 하면, 팀이 30%를 추가하여 완성한다"
에디터 노트: AI는 도구일 뿐
바이브 코딩의 등장은 흥미로운 현상입니다. 하지만 중요한 깨달음은 이것입니다:
"빠르다"는 것이 "좋다"는 것은 아닙니다.
48시간에 만든 앱이 3명의 스크린 리더 사용자를 제외하고 완벽하다면, 그것은 실패한 것입니다. 2주 만에 배포했지만 모바일 사용자가 40% 이탈한다면, 그것도 실패입니다.
바이브 코딩의 가치는 "빠르게 배우기"입니다. AI를 사용하여 초기 버전을 빠르게 만들되, 사용자 피드백에 기반해 품질을 계속 개선하는 것입니다.
이를 위해서는 위에서 제시한 감사 프레임워크가 필수입니다. 자동화된 도구, 명확한 체크리스트, 반복적 개선 사이클이 있을 때만, AI 코드는 진정한 가치를 발휘합니다.
2026년의 최고의 팀은 "AI를 잘 사용하는 팀"이 아닙니다. 그것은 "AI의 한계를 이해하고, 그것을 보완하는 팀"입니다.
결론: 감사 없는 배포는 도박이다
AI가 코드를 생성할 수 있다는 사실은 놀랍습니다. 하지만 그 코드가 실제로 사용자에게 가치를 제공하는지는 별개의 문제입니다.
이 기사에서 제시한 감사 프레임워크는 단순한 체크리스트가 아닙니다. 이것은 AI 시대의 품질 보증 철학입니다:
- 성능을 측정하지 않으면, 최적화할 수 없다
- 접근성을 검사하지 않으면, 사용자를 제외하고 있는 것이다
- 반응형을 테스트하지 않으면, 대부분의 사용자를 무시하는 것이다
- 보안을 검증하지 않으면, 데이터를 위험에 빠뜨리는 것이다
바이브 코딩은 빠를 수 있지만, 무책임할 수 없습니다.
Where AI Drives UX, FRAMEOUT